I love my data and do everything I can to keep it. When I recently rebuilt my home server I took the opportunity to improve my backuprecovery strategy in case the worst happens. Here’s the new setup:
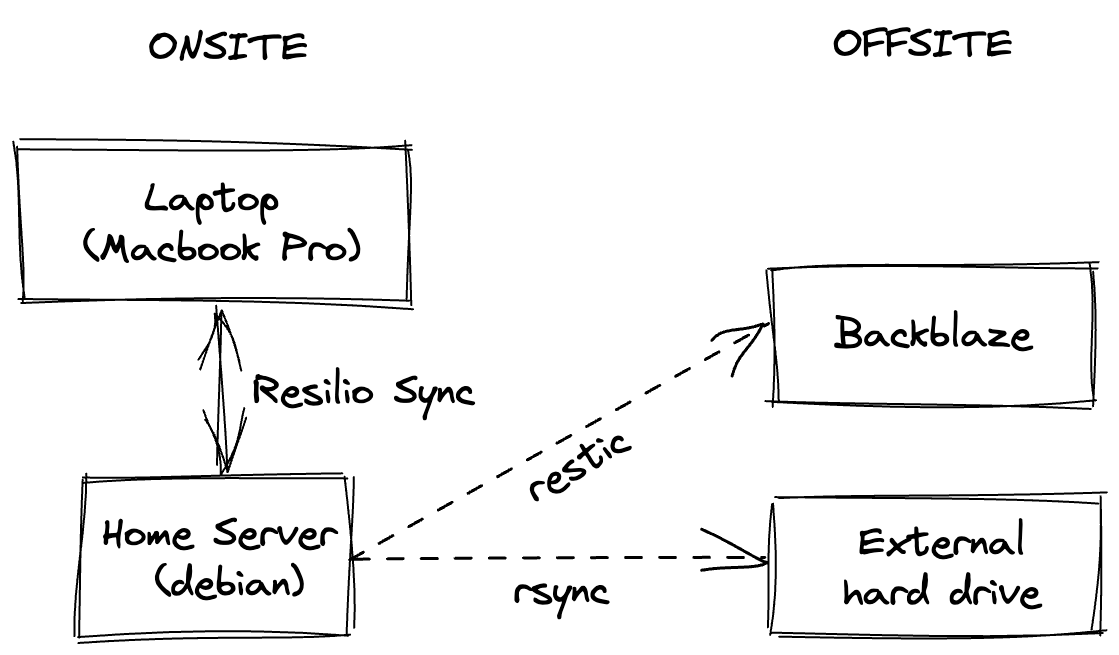
I have two sets of files I care about:
- Documents: stored on the laptop and home server
- Media library: stored only on the home server
Documents are stored on my laptop and synced with my home server using Resilio Sync. I prefer this to Apple’s Time Machine, as I can access my documents from elsewhere when I don’t have my laptop on me: either using my phone with their iOS client, or over an SSH connection.
Online backups on my home server
ZFS volumes are snapshotted daily; the defaults provided by the zfs-auto-snapshot package were fine for me so it was as simple as running
sudo apt-get install zfs-auto-snapshot
Cloud backups
Restic backups up to a Backblaze volume weekly.
Offline backups
rsnapshot copies to a LUKS-encrypted volume on external hard drive, which I keep off-site and update every month or so.
Testing
The old adage goes that you’re only as good as your last restore, so I have some automated restore testing in place. I don’t do complete restore tests for a couple of cost reasons: I don’t want to pay the egress costs, nor do I have enough disk space lying around to restore onto. Instead I:
- Use
restic checkto verify 1% of the backup weekly - Restore a test corpus of files weekly and compare them to the source. A new file is added weekly to the corpus through a cronjob with contents from /dev/urandom, and a comparison made between the two.
Here’s the simple script to create the test file, executed weekly through the cron:
#! /bin/bash
set -e
TEST_DIRECTORY=/vol/1/restic-restore-test/
TEST_FILE=$TEST_DIRECTORY/test-`date +%s`
dd if=/dev/random of=$TEST_FILE count=1024 >/dev/null 2>&1
And the script that performs a test restore:
#! /bin/bash
set -e
. /etc/restic-env
RESTORE_DIR=`mktemp -d`
cleanup() {
/usr/bin/rm -r "${RESTORE_DIR}"
}
trap \
"{ exit 255; }" \
SIGINT SIGTERM ERR EXIT
TEST_DIRECTORY=/vol/1/restic-restore-test/
LAST_BACKUP_TS=`restic snapshots latest --json | jq -r 'max_by(.time) | .time'`
## Restore test corpus from the latest backup
restic -r $RESTIC_REPOSITORY \
restore latest \
--target $RESTORE_DIR \
--path "/vol" \
--include $TEST_DIRECTORY \
--host redacted
## Get a list of the local files in the test corpus created before the backup
LOCAL_FILES=`cd $TEST_DIRECTORY && find . -type f -not -newerct $LAST_BACKUP_TS`
## Diff 'em
if [ -z "$LOCAL_FILES" ]; then
echo "No local test corpus found so can't compare!"
exit 1
fi
for LOCAL_FILE in $LOCAL_FILES
do
diff ${TEST_DIRECTORY}${LOCAL_FILE} ${RESTORE_DIR}${TEST_DIRECTORY}${LOCAL_FILE}
done
echo "restic_test_corpus_restore_ts `date +%s`" > /var/lib/prometheus/node-exporter/restic-test-restore.prom
cleanup
Monitoring and alerting
Prometheus alerts are configured for stale backups:
- A “last offline backup stale alert” is my reminder to go get the off-site disk, bring it home and do a backup.
- A “Cloud backup stale alert” looks at
restic statusand fires if it was more than 8 days ago.
Both of these just use a metric that’s written to a local file on backup completion with the current timestamp, which the node exporter picks up.
Room for improvement
- Append-only backup keys: Unfortunately restic to backblaze doesn’t support append-only mode, so my home server has credentials on it with a little too much power. If the server were compromised someone could wipe my cloud backups. This is a risk I’m willing to take as I also have the off-site backup, but I’d like to clean this up and only have credentials on the home server that allow creation of new backups.
- Consider moving everything to the cloud and switching off my home server
- Documents: I already use cloud storage for some documents, but I keep more confidential things off the cloud. Maybe this isn’t the right trade-off, I should revisit it.
- Media library: this used to be cost-prohibitive.
blog comments powered by Disqus