
![]()
ITX: Teletext for the World Wide Web.
The purpose of ITX is to enable users of the World Wide Web to access the vast array of Teletext information using a standard web browser. Teletext is transmitted in the Vertical Blanking Interval of a television signal. The data feed can be accessed from a PC using specialised hardware such as a television decoder card.
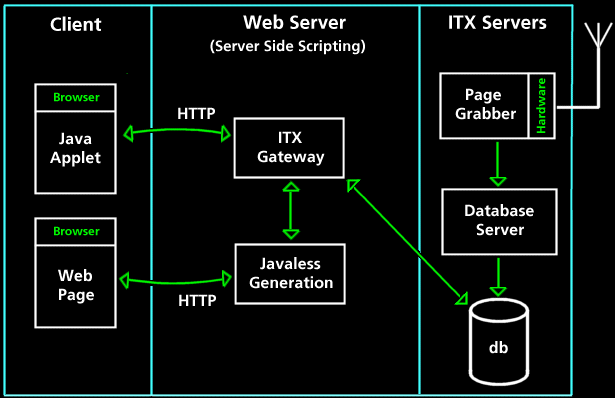
The group did not wish to prohibit access to the system by imposing specific client technology restrictions, and thus decided to implement the user front-end in two ways. The first client implementation was in Java. This delivers an application-like interface, as expected of modern software.
The client generates images from the raw page data, which has the advantage of a low server load and only minimal data transfer between the client and the server. Thus, it is perfectly suited for access over the even the slowest modem links.
The second implementation uses the server scripting technology of PHP to generate clickable images of pages and pass them on to the client. Most of the functionality of a full-blown application is still delivered, by moving the intelligence to the ITX Gateway. This is good for thin clients without an appropriate implementation of Java, or where administrative policies prohibit use of code running locally. Load on the server is high which could limit the number of users at one time. However, with the implemented architecture the system scales well to multiple servers.
Discussion is made of how the server architecture has been designed with this modularity in mind, enabling the system to perform as demand grows. The server architecture also mirrors the nature of the distribution of Teletext information. Through the servers, the notional stream of data is maintained until it is stored into a database. This provides significant added value to the project, as response times are far faster than when using a television set.
Further advantages are delivered through the ITX Gateway, which can perform searching across all channels held in the database. Search results are returned with thumbnails, providing quick access to the information needed. Similarly, a user can store favourites with the ITX Gateway, which are also returned in a similar manner.
A Java-enabled web browser that implements the Swing libraries e.g. Netscape Communicator 4.7.
Simply open the following web page to start the applet: live/index.php3 (if you are reading this from a CD, you may wish to skip down to the Installation Guide).
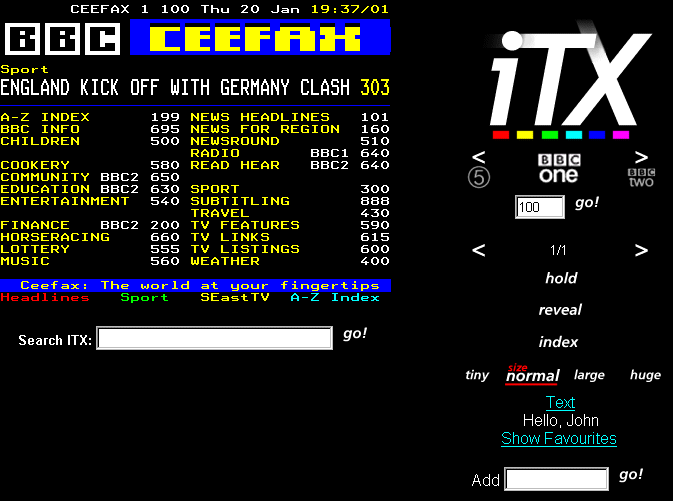
Upon loading you will be presented with a toolbar at the top of the applet. This is used to select a channel, a page and a sub-page. The grey strip on the left-hand edge of the toolbar can be used to position it on any edge of the applet or it can dragged clear altogether in which case it will appear as a separate window. Placing the cursor over an item on the toolbar will cause a tooltip to appear, which will give a brief description of that item's function.
On the left is a box containing a logo for the current channel, click on it to select a different channel.
The three digit number is the current page number. This can be changed by clicking on the numbered buttons to enter a new page. Once a valid three-digit page number has been entered the client will go to that page. The 'I' button can be used as a shortcut to page 100, the index page and the 'P+' and 'P-' buttons can be used to go to the next and previous pages respectively.
The client will periodically switch to the next sub-page, if one exists, of its own accord. However, to go to the next or previous sub-pages immediately, click the 'S+' and 'S-' buttons respectively.
Any page numbers, web addresses or e-mail addresses that appear on a page are clickable. This means that a left mouse-click on such a link will bring up the page that it links to. When the cursor is positioned over such a link the status bar of the web browser will display where that link goes and the cursor will change to a hand.
Right clicking anywhere on the applet will display a popup menu where several other functions can be accessed.
To stop the client from periodically skipping to the next sub-page select the Hold menu item. A tick will appear next to it. Do the same again to de-select the Hold function. Reveal is used to display text that is hidden on the page by default such as the answer to a quiz question and the like. It can be toggled in the same manner as Hold.
Each user of the applet is able to set a list of favourite pages, which can be quickly accessed from this menu item. To add a new favourite select the 'Add to Favourites...' menu item at the bottom of the Favourites sub-menu. A dialog box will appear prompting for a name for the new favourite. Clicking 'OK' will add the new favourite, 'Cancel' will cancel the operation. Once a favourite has been added it will always be immediately available to the user that created it whenever they use the applet in the future.
Below the applet is a text field that can be used to search for a string across all available pages on all available channels. The results are displayed as a list of thumbnail images with the context in which the string was found. Clicking on a thumbnail will open a new applet at that page.
Simply click the browser's back button or go to another web page.
This guide gives information on the installation of the Database Server, Page Grabber and the ITX gateway.
The following software should already be installed and configured correctly on the specified machines:
/dev/vbidevice. Included on the CD-ROM is the current release of the bttv driver, release 0.6.4h. The latest version can be obtained from http://www.metzlerbros.de/bttv.html. For instructions on installing this driver, please see documentation distributed with it.
Please refer to the README file on the CD-ROM for installation instructions.
Two main paradigms exist for the design of a computerised Teletext viewer, the TV paradigm and the web-based paradigm. The TV paradigm means making the Teletext viewer as close to a normal TV's Teletext interface as possible. It demonstrates the same features and presents the information in exactly the same way. On the other hand the web based paradigm means making the Teletext pages conform to more modern practices. For instance, the graphical sections of a page could be smoothed to look vaguely more realistic or the bare text could be extracted. It was decided to keep the appearance of the Teletext pages as close to those on a TV as possible while providing some extra functionality that would not be possible on a TV. The foremost feature must surely be clickable page numbers. These will take the user straight to that page without them having to type the page number in. Also, searching all the available pages is a viable option that would not be possible on a TV.
The user interface is constructed entirely of Java Swing components. It was decided to use Swing for the user interface because of its attractiveness to the end user and its ease of use by the programmer. It is a very flexible system for user interface design that makes it very easy to get the right results. The applet is a JApplet made up of a JToolBar and a JPanel with a JPopupMenu accessible from anywhere within the applet. The behaviour of each of these components is controlled by Action Listeners which are all passed a pointer to the applet itself so that they may easily access all the variables and methods in the entire applet.
It was quickly realised that the most used Teletext functions should be available on a toolbar while other, less used, functions should be hidden away on a popup menu to avoid cluttering the screen. The use of a JToolBar allows the toolbar to be docked against any side of the applet and also to be floating in its own resizable window.
A non-editable JComboBox has been used to select the desired channel. The logos of the channels have been used to improve user-friendliness. The page number will reset to 100 each time a new channel is selected, as it would be in a normal TV.
The classes interact by calling methods on each other. Virtually all the classes are passed a pointer to the applet so that they may easily access any other class within the entire applet. This also works well for interaction between threads as they effectively have a shared data structure.
The user interface does not interact directly with the server, rather it passes it's page requests to RequestHandler.getPage() and causes a page to be rendered by calling DisplayedPage.render().
The user interface consists of the following classes:
Upon initialisation the applet will create a new remote, display and popupmenu. The remote will load the images it requires for its buttons, the popup menu will create its menu and also acquire the user's list of favourites, the display will create graphics spaces for the renderer to write to.
The user interface is fully threaded to greatly improve performance with the remote and the Teletext display being separate threads.
The applet can accept four parameters from the HTML page that opened it. These specify the initial channel, page and subpage and also the current user. This means that using a simple server side php3 script a single Teletext page can be addressed as a URL. This is used in the Favourites system described below.
Upon running the remote will simply listen for user input and not do anything until then. When a button is pressed it will update the page display an when it detects a valid page number it will call the request handler with that page number. The channel selector behaves in a similar way. When a new channel is selected it will call the request handler as before with the new channel number and page 100. The layout of the remote is controlled by the ITXRemoteComponentListener which updates the layout every time the remote is resized or switched between its docked and floating states.
The popup menu is called by the ITXPopupController which will retrieve the co-ordinates of the mouse pointer and display the menu at that position. Once this is done, the ITXMenuActionListener monitors the state of the menu and acts upon a selection. It will set or unset the hold and reveal booleans as required and manage the favourites system described below. It was soon noticed that the ITXPopupController could be easily extended to support clickable links. Every time a mouse button is pressed the controller calls the Hotlist.find() method with the mouse co-ordinates. If a HotItem is returned, the client will get that page or URL. However, to provide user feedback as to whether or not the pointer was over a link required a different kind of controller, one that constantly monitors the position of the mouse, updates the status bar and changes the pointer to a hand when the mouse is over a link. This is done by an ITXHandController. Again, this uses the Hotlist.find() to determine what is where.
The Favourites system is very tightly woven with the ITX server. The server starts the applet with a user parameter in the HTML tag. The client then gets that user's list of favourites from the server and displays it on a sub-menu of the popup menu. When the user wishes to add a new favourite they are prompted for a name for the page. This name is sent back to the server along with the page, subpage and channel. The server adds the favourite to the user's entry in the favourites list database and returns OK if everything went according to plan. The client will then re-enquire from the server what the favourites list is and re-initialise the menu accordingly.
The display thread calls the Displayedpage.render() method every second with the correct page to display. This must be done to implement flashing, reveal and displaying the next subpage. This thread does all the management of pages. It selects a page according to whether or not the reveal boolean is set and whether a flashing page is being displayed. If the hold boolean is set, it will not display new subpages, and just keep displaying the correct state of the current subpage.
Hotlists are used to store information about what areas of a page are clickable and what should be done when they are clicked. A Hotlist is a linked list of Hotitems, which has PageLink, URLLink and MailLink as sub-classes. A HotItem holds a Rectangle that refers to the area that is clickable. A PageLink contains a PageAddress which stores the relevant page, subpage and channel information. A URLLink contains a target URL which will be opened in a separate window and a MailLink contains an e-mail address which can be opened in a mailing program.
The Java Client could be developed into a stand-alone program that offers many extra features such as:
The servicing of user requests of pages is carried out by the request handler, which gets, parses and renders the pages into images to be displayed by the user interface
The architecture was chosen because to make the response time to user requests as low as possible and maximise the portability of the applet. All requests are made over HTTP to allow them to pass through corporate firewalls to ensure correct operation in diverse environments. The grabbing and parsing are done in different treads from the user-interface to ensure that the UI remains responsive while they run and to allow the creation of several Grabbers and Parsers to get page requests concurrently. To maximise responsiveness pre-emptive caching to a local cache was implemented. Whenever a page requested by the user arrives it is parsed and all the page numbers on that page are detected (along with a few unavoidable things such as Test scores). These and the fasttext links are the most likely pages for the user to want to visit next, therefore these pages are retrieved from the server and stored. The final rendering is done using GraphicFont, this is a freely available and powerful tool for creating and using custom-fonts in Java written by Kevin Hughes.
The different classes mostly interact by calling methods on one another. However, the different threads use shared Synchronized data structures to ensure the correctness of their data and to eliminate the possibility of deadlock, in particular between the grabber and parser threads.
To the user interface the request handler presents the methods RequestHandler.getPage(PageAddress p) to get pages and the DisplayedPage class to render the pages.
The request handler consists of the following major classes:
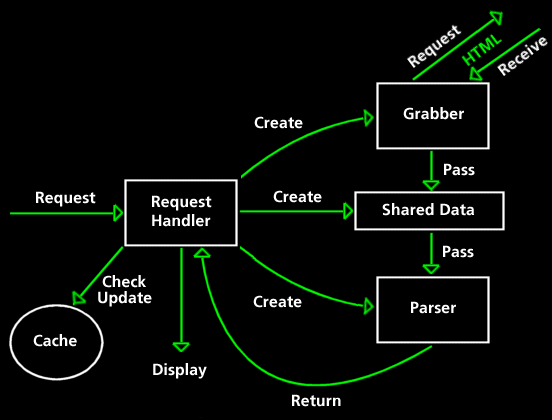
When the User wants a new page the UI calls Requesthandler.getPage(PageAddress p) (PageAddress is a class that stores a pages' channel, pagenumber and subpagenumber). This method tries to get the page from the cache. The cache will return the page iff it is in the cache and it has not expired, else it will return null. If the cache has returned a page it is displayed immediately. The request handler then proceeds to get the page, irrespective of whether it is in the cache to ensure that the user has the latest version.
The cache stores a LinkedList of ParsedPages. The list is limited in size to 100 items to prevent the cache growing to large in an extended session of use and causing an OutOfMemoryError. When adding a new page the cache first checks to see if the page is already in the cache, if it does then the old copy is deleted. The page is then added to the list and the count incremented. If this brings it over the size limit then an attempt is made to free up room by deleting all pages who have expired. If this fails to free any spaces then the first item in the list is removed.
When getting a page the cache will check to see if the page is in the list. If it is not it returns a null value. If the page is in the cache but has expired, the page is removed from the cache and null is returned. If the page is in the cache and is still valid it is returned.
To get a page the Request handler creates a new Parser/Grabber pair with arguments of the PageAddress to get, the RequestHandler, the applet(to give the correct URL for the server) and the three GraphicFonts to be used to draw the pages.
The parser grabber pair creates a GrabbedPages, a Parser thread and a Grabber thread and starts the Parser and Grabber
The GrabbedPages class stores the list of pages to be fetched by the Grabber and a list of Grabbed pages. The Grabbed pages deals with synchronisation between the Grabber and the Parser thread. Its methods are is Synchronized to prevent any deadlocks. As well as the Lists it stores two boolean variables. One is set by the parser when it has stopped adding pages to the list to get and the other is set by the grabber when it has finished getting the pages in the list. By monitoring these variables the Parser and Grabber threads know when there work is finished. All the methods of the Grabbed pages are synchronised to prevent the possibility of deadlock
The run method of the Grabber first creates a list of the pages it has got so far, this list will allow it to ensure that it does not get the same page more than once. It then enters a while loop which checks that the GrabbedPages still stores more pages to get. If this returns true then is attempts to get a PageAddress. If there are currently no pages to get then the thread will be blocked and wait until a new PageAddress is put in the list. When the method returns with a PageAddress the gotpages list is checked to ensure that this page has not been got before. If the address is not in the list a new URL is formed from the applet's codebase + servepage.php3?channel + the required parameters from the PageAddress. This URL is used to create a new GrabbedPage is set up to get the page. When the page has been received it is added to the list of grabbed pages and any waiting threads are notified. When there are no pages left to get the Grabber sets GrabbedPages.finished to true and terminates;
The run method of the Parser enters a while loop checking if there are still pages to be parsed (either there are pages in the list or the grabber thread reserves the right to add more). If there are still pages to be parsed it attempts to get one from the list. If the list is empty the thread blocks and waits for more GrabbedPages to be put in. when the method returns with a GrabbedPage the Parser creates a new ParsedPage from it. If it is the first page this thread has created it extracts the list of pages linked to from the new page, and adds these to the toget list. See Pre-emptive Caching. It then tells the GrabbedPages that it is going to add no more PageAddress. The ParsedPage is then returned to the RequestHandler for displaying. When there are no more GrabbedPages to parse the thread terminates.
A grabbed page gets and stores the unparsed data for a Teletext page. It stores the PageAddress of the page, its expiry time and a list of its sub pages as GrabbedSubPages (n.b. in this definition all pages consist of at least one subpage). In its constructor it takes A URL and it opens this URL as a BufferedInputStream, this allows the data returned by the server to be read in byte by byte without losing any of the Teletext control codes. First the status is read, if the query has been successful this will start "+OK", else it will start "-ERR". If an error has been returned e.g. "-ERR02 Page not found in Database" then the GrabbedPage has no subpages and an ITXException is thrown to the user interface to allow it to display a user friendly error message. Otherwise the number of subpages and the time to live is read, the time to live is added to the current system time to give and expiry time to this page. For each subpage a new GrabbedSubPage is created. The GrabbedSubPage stores the fasttext links, and an array of rows.
A ParsedPage is a page of Teletext parsed and stored in a format ready for rendering. Each ParsedPage is related to a Grabbed Page and they store the same basic data. In place of the GrabbedSubPages there are ParsedSubPages. However, whilst most of the work of getting a page was done by the GrabbedPage, most of the work of parsing a page is done at the subpage level.
The ParsedSubPages stores the pages as lists of TeletextStrings, each TeletextString has associated with it a foreground colour, a background colour, a position, a font (text or graphics or separated) and the text itself. Splitting the text this way into lists of strings with similar properties helps to reduce the rendering time of the page in GraphicFont In the constructor of the ParsedSubPage it is passed a GrabbedSubPage to parse, and the three fonts to render the strings with. The fastext links and the address are extracted form the GrabbedSubPage, and then each Row is extracted in turn and parsed.
At the start of parsing a row variables describing qualities of the output text such as reveal, flashing and colour are set to their default states. The whole row is then checked to see if it contains any double height control codes, in which case the whole row will be double height. This is not what is implied by the spec, as evidenced by the existence of a not double height control code but it does appear to be what is done by TVs and gives better results. The Parsing of the row is done byte by byte. Each byte is read in and checked, all visible characters are added to the currently read string, if it is a number, an @ symbol or a dot in the middle of a word a note is made to check this word for possible links later. If a control code is found the current string is stored as a Teletext string with the current settings, then the settings are changed to reflect the effect of the control code and a new string is started.
If the parsing above indicated that there is a possible page link, URL link or email link on this page the word in which it occurred is analysed in more detail. For page links it checks that the last three characters of the word are numbers, and that the fourth last is an acceptable character (space, any control character, p, P or .) This ensures a good compromise between finding all valid links and avoiding fake ones, in particular it screens out monetary amounts like £300. A URL is detected if is starts either "http://" or "www." and ends with .?? or .???. An email address must contain an @ an also end .?? or .???. These Links are put into HotItems and built into hotlists which are used for the pre-emptive cacheing and the clickable links.
The ParsedSubPage class also provides four methods for rendering normal text, flashing text, revealed text and revealed flashing text. In each method the appropriate TeletextStringLists are rendered at the appropriate position and size using GraphicFont.
When a page is returned by a Parser thread to the RequestHandler it caches the page and then checks to see if it is the one that the user is waiting for. If this is the case it calls DisplayedPage.setPage(ParsedPage p).
The DisplayedPage class stores the page that is currently on display and has links to a two dimensional [4][2] array of images. The first dimension of this array has buffers for normal, flashing, reveal and flashingreveal images, the second dimension gives a buffer to which the next subpage can be rendered, giving a seamless transition between subpages. Unfortunately these buffers, while enabling flashing and smoothing the transitions between subpages do require a large amount of memory, and are the main limiting factor on the size of the display. It was decided that the images should be displayed to the user while they are being drawn so as to give the user some information about how the downloading and rendering of the requested page are going.
A class written by Kevin Hughes was adapted to provide a way to implement fonts where it is not possible to install then on each machine locally. The font used was a pixel perfect representation of the font used by the BBC micro computer to draw Teletext. Whilst comparing the output from a TV it was noticed that the percent symbol was different. Further investigations showed that the Teletext alphanumeric characters are encoded on a 6 by 9 grid on the BBC micro and on a 12 by 10 grid on a TV. A new gif image for Graphic Font was constructed to emulate text more fully but when tested it was too slow and generated very large images which were slow to load. It was also decided not to deploy the separated graphics font because it also had to be encoded on a larger grid and it was decided to use the contiguous font for all graphics characters to improve performance.
As stated in report 2, Graphic Font supports features which are not required in this application such as anti-aliasing. The graphics characters can be generated from the character codes directly so do not need encoding. Encoding the font as images wastes space as numeric values must be encoded as RGB values along with the pixel representation of the font.
An alternative design for a custom font class was devised which would allow a text file to encode the font. This would greatly save space. The text file could be read into the class and used to create an array for each character. See format below.
10 // Height of each character 12 // Width of each character 65 // Character code ~~~~~~~~~~~~ // ~ is white @ is black ~~~~@@@@~~~~ ~~~@@~~@@~~~ ~~@@~~~~@@~~ ~@@~~~~~~@@~ ~@@@@@@@@@@~ ~@@~~~~~~@@~ ~@@~~~~~~@@~ ~~~~~~~~~~~~ ~~~~~~~~~~~~ 66 ~~~~~~~~~~~~ ~~@@@@@@@@~~ ~~@@~~~~~@@~ ~~@@~~~~~@@~ ~~@@@@@@@@~~ ~~@@~~~~~@@~ ~~@@~~~~~@@~ ~~@@@@@@@@~~ ~~~~~~~~~~~~ ~~~~~~~~~~~~ . . .
To render a string each character representation could be copied into a byte array and converted into an image with the following code.
image = Toolkit.getDefaultToolkit().createImage(new MemoryImageSource(int w, int h, int[] pix, int off, int scan));
Due to time constraints this was never implemented but would have resulted in a big speed improvement in the Java client which would have improved the overall result greatly.
A few things could be improved about the request handling. As currently implemented the display size is very small for the above reasons. the usability of the applet could be considerably improved if it could be made bigger. Java does provide methods to draw images scaled, but when tried these produced unpredictable and unwelcome side effects such as the background of the pages turning blue. With a little more time it should be possible to find out what is causing this problem and remove it to make the pages more readable.
Also as it currently stands the Parser and Grabber threads do not properly terminate and release there memory, and so after long sessions it is possible to get OutOFMemoryErrors. Overall the speed and Stability of the applet could be improved, especially when running in browser. It would help if the browsers would support the latest versions of Java, and in a stable and fast implementation.
The behaviour of the buffers when changing between subpages is not perfect, and when the program is running slowly strange effects like text flashing between two colours is seen. This does not seriously affect usability, but does spoil the picture.
There is room for a more effective caching algorithm, which would make more use of the expiry date of pages to only download the files which are not in the cache or are nearing there expiry date, e.g. a file nearing its expiry date would be valid to be shown, but would using it would cause the request handler to go and fetch a more recent one. This would be made more effective with some sort of server generated statistics to say how often a page actually changes, a difficult task
The potentially biggest improvement that could be made would be the rewriting of GraphicFont. GraphicFont has support for a lot of superfluous features such as anti-aliasing and therefore can be a little slow to render. Given the simplicity of the Teletext font, and more so of the Graphics fonts it should be possible to create a class to render them efficiently, as discussed in the GraphicFont section above.
Server side scripting was used to provide
An early choice was made to keep the features used of PHP to those of a typical installation, rather than require any esoteric add-ons to be installed. This means that the ITX Gateway can be placed on any convenient web server, rather than requiring a dedicated server. No extraordinary access is required for the scripts to run successfully. For the duration of the project the scripts were installed in a user directory of www.doc.ic.ac.uk, the departmental web server.
The key objective was to provide as much of the functionality deliverable by a full application, but moving the intelligence to the server. This offers a useful alternative where the target browser does not have Java, as well as allowing access to thin clients such as mobile phones and other handheld devices.
The Javaless Generation uses two PHP scripts to deliver the information to the browser:
getpage.php3 writes out HTML to
display a table of controls, an image tag pointing to genimg.php3
and a map of the clickable links for this page. In textonly mode
the image is replaced by a textonly version of the page, which is useful for
copying and pasting information from Teletext pages. If quietly
is set, then most controls are not displayed, which is useful for
synchronising pages to a handheld device through a service like AvantGo (www.avantgo.com).
genimg.php3 Since this is the 'fallback' alternative, it was important to ensure that it would work in practically any browser, without assuming any particular advanced features. The core features of HTML used are all several years old, and can be assumed to be widespread. To provide for clients which cannot display graphics, a text only interpretation of the page can also be requested. This benefits those who want to cut and paste data from a page, and also those accessing from mobile devices, with small, low resolution screens.
Making a clear and simple user interface was critical to the usability of the Javaless Client. Since the response time is likely to be slower than a local application, it is especially important that the interface makes it clear what actions are being performed.
The decision to make the Java Client follow the TV paradigm, but offer the extended functionality available or even expected on the web were carried through to the Javaless Client. The client mirrors the behaviour of a television set. When changing channels it resets to page 100, when holding, there is a visible cue that the page is held. It also avoids some of the less desirable behaviour of a traditional set; when releasing a held page, it continues on to the next subpage,
The benefits to using a good image generation library were significant. GD library's functions are well integrated into PHP's image generation. GD provided the ability to load custom made fonts and draw arbitrary strings into the image to emulate Teletext successfully. The overall effect is an accurate rendition of each Teletext page, generated dynamically in a reasonably short time. Early investigation into GD and PHP showed that these were the appropriate tools for the job. There were complications due to interesting documentation for GD fonts in particular, which are detailed in the Implementation section.
User responses to the interface led to a number of changes, including the addition of some of the most useful features, notably the ability to adjust the size of the Teletext output to suit people with higher resolution displays and more visual cues for the channel controls.
It was decided not to use frames in the HTML, simply because they only add unnecessary complexity in browser (mis)behaviour, reduce accessibility. An advantage would have been the ability to hide some of the complex information being passed within the URL (a typical URL looks something like getpage.php3?chan=1&page=112&scale=100&subp=0&hold=1&revl= 0).
By relying on the standard caching for web pages, the benefit of client-side caching will still be felt, without any explicit code from this project.
The key interfaces are to the ITX Gateway scripts, which are spelt out in detail in the following section, and to the user, which is discussed above.
Purely because of the environment we are running in, little can be assumed of the capabilities of the client. All the intelligence must be wrapped up on the server, delivering simple pages with little more than text, links and images.
It should be noted that the entire interface works happily in a text browser also, making broad access to the Teletext information a reality.
genimg.php3 This script is responsible for
generating a representative image of the Teletext page. It fetches the page
data via the ITX Gateway, breaks it down into lines of 40 characters each, and
then calls outputline() for each line.
outputline() keeps a number of state variables to keep track of
all the different modes that can be set through control codes. Unsupported
states are still tracked, to aid the addition of such features in future, if
desired. For instance, GD library does not support animated GIFs, so flashing
text remains solid, but $state_flash still holds the required
information should a more convenient library become available.
Without going into great detail of how the Teletext page is arranged, it is
enough to say that there are a sequence of 40 bytes for each line, each of
which represents a printable character or a control code. Where a control
character is found, it alters the state, either at of after the character
being drawn. Where a printable character is found it may come from one of
three overlapping fonts, in any of seven colours, with a variety of other
properties such as whether it should be concealed, displayed in double height,
and so forth. The particular output of a character depends solely on the
characters which precede it on that line, so the problem is well modelled
using a function iterating over the line. Depending on the
$state_* variables, each character is drawn out by either
outputtext() or outputgfx() in the appropriate style
and colour.
outputtext() uses a GD font constructed for
the project. It is much easier to see how a GD font is arranged by examining
one than by looking at the sparse documentation (save for the meaning of the
first 16 bytes). Some trouble was had at first in putting everything in
precisely the correct format. On looking for more information, most sources
described GD fonts as old and on the way out, in favour of broad support for
scalable TrueType fonts. However, for the needs of Teletext a bitmap font is
precisely what is required and once the font was formatted properly, the
performance in writing characters into the graphic was most impressive.
outputgfx() does not need to resort to a font, since the
bit-pattern for any graphic character details which of six regions need to be
filled or not. Thus a translation can be made to just draw the required
rectangle directly onto the canvas. At first, simple bitwise operations were
attempted to achieve the desired result. Unfortunately, the bitwise operations
would not work properly in PHP for the character values when using the upper
bits; it is possible to take a newly defined hex value and a character for
which bin2hex() returns the same value, and find they behave
differently! Thus, at the expense of elegance, a straight translation table is
used to look up each value as required. outputgfx() draws
characters in either separated or contiguous modes, as dictated by the state.
There are complexities of the behaviour of held graphics characters which are not fully documented here, but left as an exercise for the reader. The available documentation conflicts in it's description and is generally unclear. This implementation attempts to interpret the intended meaning of the specification of September 1976 and the further considerations ("Possible application to 525/60 Systems") and tinge it with practical observation based on what a television produces for a number of pages which use this mode. This implementation agrees with the television set on the tested samples, but it cannot follow all of the documented behaviour.
getpage.php3 This script acts as the main
control loop for the 'Javaless Client'. It acts by creating links back to
itself with modified parameters. There are two purposes. The first is
relatively just a case of keeping track of the present state and offering
links to all reasonable next states. This means coping with wrapping the
channel and subpage numbers appropriately, based on information gleaned from
channels.inc and the ITX Gateway. getpage.php3
outputs a tag in the head of the document when the page is to flip to the next
subpage, that is whenever the document has subpages and the page is not held.
getpage.php3 also handles various parameters that affect
the display of the page, scale takes a percentage value to scale
the display by, with sensible values of 50, 100, 150 and 200 offered through
the interface. It will properly calculate for other values (adjusting the map
appropriately), but depending on the algorithm your browser uses to do the
scaling (which is generally a quick and nasty one), the display may not be
very pretty. As display technology improves, it would likely be necessary to
increase the size of the output, so parameterising this seems like a good
idea. The latest technologies can easily produce resolutions in the 2-3000
pixel range, and this is only likely to be on the increase. Ideally, a user
would specify what sizes tiny, normal, large and huge related to for them.
The other major function of getpage.php3 is to produce
the image map for the present page, when in graphics mode. It makes extensive
use of regular expressions in order to strip the Teletext data of unwanted
control codes and pull apart each line to find reasonable email addresses,
URLs and page numbers which are to be clickable.
Since the fastext links at the bottom of the page may be of varying length it is also necessary to pull this line apart to determine the length of each link. This is done by looking for the character colour codes of Teletext to find the boundaries. This is another area where we can add extra value over using a television set, since the browser gives feedback as to where a link points to, even for the Index link, which is traditionally a somewhat hit and miss affair (is it the index to this section, or page 100?).
The purpose of the ITX Gateway is to provide access to the data stored by a Database Server.
The addition of the searching feature is an excellent example of how putting Teletext on the web offers significant added value when compared with looking for information from a television. The traditional approach of hunting around in the indices for the pertinent section, and then hunting through that for the information required is labourious; and if you started on the wrong channel, your efforts could be frustrated as you find that the required page is on BBC Two rather than One. Being able to quickly find the appropriate pages across all channels is a great boon.
The key choice made was to deliver the information to the client over HTTP. This has the considerable advantage of working in practically any web environment, irrespective of firewalls and other configuration issues. From there, it is a natural step to use scripts running on a web server to collate the necessary information from the database. The remaining choice is one of which scripting language to use on the server.
PHP was chosen for a number of reasons, it has very good hooks for querying databases, particularly MySQL, as well as the advantages for the Javaless Generation scripts described above.
The ITX Gateway fetches information from the database on request from either client. For page data, a client can request either all subpages of a particular page, by asking for a (channel, page) or for a particular subpage by asking for (channel, page, subpage). For searching, the Gateway responds to a simple HTML form, returning an HTML page returning links to web locations which will restart whichever client at the appropriate channel and page. For user preferences, the Gateway can return either the list of this user's preferences to the Java Client, or an HTML page linking to the user's favourites, as for the searching.
Connection to the database is as outlined in Interfaces for User Preferences below.
The ITX Gateway consists of five PHP scripts in
all - index.php3, servepage.php3,
servefave.php3, storefave.php3,
search.php3.
index.php3 is a simple harness
that simply sets up the applet with appropriate parameters, offers a link to
the Javaless version, and has a search box, for which the results come back to
the applet. Given a parameter of forcenojava=1, it forwards the
browser directly to the Javaless version.
Each script queries the database using SQL and then returns the required information to the client.
servepage.php3 offers two distinct modes. The first is
primarily for the Java Client, to take advantage of the client-side caching.
It takes two parameters, channel and pagenum, and delivers a simply formatted
file which contains all the subpages of the requested page. The format is as
follows:
+OK<newline>
Total number of subpages, n<newline>
Time to live (in seconds)<newline>
n blocks of {
Length of forthcoming data section<newline>
Fastext links (30characters)*
Data section
}
* - 3 chars page and 3 for subpage for each of
Red, Green, Yellow, Blue and Index links.
If an error occurs: "-ERR errormessage<newline>" is returned.
servepage.php3's other function is to return a single particular
subpage for the Javaless Client, which has means to store the extended
information. The format is similar to that above, but without the length of
data block field.
servefave.php3 returns the list of the
given user's favourites, or an HTML page containing a thumbnail and link to
each favourite.
storefave.php3 stores a new favourite
for a user. For the Java Client, a return code is sent, indicating
+OK or -ERR. For the Javaless version it simply
writes out an HTTP header sending the browser back to the page submitted, with
a result code indicating success or failure of adding the new favourite. This
enables a seamless acknowledgement of the user's action in the Javaless
Client.
search.php3 finds all the pages which contain
the user's query and returns thumbnails with links to all of them. The HTML is
formatted to ensure the speediest possible display in the browser (by
specifying table widths and image sizes) even before the many thumbnails have
loaded. The load this script places on the server should be examined if the
system was to be rolled out on a larger scale. It may be advisable to only
generate thumbnails for the first five or ten results, since the work to
produce a thumbnail is comparable to that for a full page.
The ITX Gateway could be used to perform load balancing across a number of databases. Similarly, the Gateway could return links to a different Gateway if there is a closer one to the user. Providing such functionality seamlessly without compromising accessibility or performance would be a very interesting, if challenging, project.
More preferences stored server-side, page refresh rate etc. Smarter sharing of user preferences under distribution, mirroring data on all databases.
Chopping of search results into pages of ten or twenty results would have made the search facility more friendly to use for searches with many results.
The ability to specify a more particular search, including several terms and looking for any or all terms, across selected channels would not be difficult to add to the existing system.
A fuzzy algorithm for searching, with results ordered by confidence would be the next logical progression.
The ITX system stores user preferences such as favourites, and thus needs to recognise someone who has used the system already to return their preferences. However, it was decided at an early stage of the project that this should be unobtrusive - users should be able to use the system whether or not they have logged in. They may have reduced functionality, but they should be able to use all parts of the system except user-specific areas. The information held on each user is not particularly sensitive so a high level of security need not be applied. However, it would be undesirable for one user to gain access to another's preferences.
In designing the user authentication module it was a high priority that the system would work in as many scenarios as possible, ranging from public access machines to home computers. Therefore, a solution using multiple techniques was required.
Cookies can be used where the user has their own setting on a particular system, be it a standalone machine or a networked workstation. This means that a user does not need to re-authenticate themselves each time they enter the ITX system, since their username and a hash of their password are stored on their local machine. These get presented to the ITX gateway at each access, and thus over multiple sessions. However, there are situations in which a cookie is not appropriate. Some users are wary of accepting cookies from sites, and may have disabled them. Public access machines may not, indeed really should not, store cookies for security reasons.
In order not to restrict user preferences to those users with cookies enabled, an alternative fall-back method of passing the username and a hash of the password as URL parameters of the page scripts was implemented.
Only a hash of the user's password is stored, so that the original can not be obtained. It was decided to use the MD5 algorithm as the hashing function as it is well-documented and functions are available in PHP to calculate an MD5 hash.
Communication is made directly with the database
using the MySQL API built-in to PHP. A connection is initiated
using the dbconnect.inc script. Please refer to the PHP Manual (http://www.php.net/manual/) for a full
list of the MySQL API.
When the main ITX page is displayed, the user is authenticated. If they are not recognised a logon box is display at the bottom of the screen as well as a Register link to enable a new user to sign up. When logging on, a check box "Remember me in future" is displayed. If this box is checked when the user submits their credentials, the server will attempt to set a cookie containing their username and an MD5 hash of their password so they can login automatically in future. If it's not checked, or the user's browser doesn't accept cookies, the URL parameter method is used.
There is no standard way in which the server can know if the user's browser accepts cookies, so a test cookie is set during the logon phase. The value of this cookie is then checked in another script when deciding whether to use cookies or not. If the cookie hasn't got a value, then the client isn't accepting cookies so the URL method is selected.
For added security, if the URL parameter method is used, the notion of a session key rather than a password is used. This stops an invalid user authenticating by using the 'Back' or 'History' functions on a browser. In order to generate a session key the existing MD5 hash of the user's password is concatenated with the current date, and the MD5 hash of this stored. Therefore, when a authentication request is made, the same function is applied to the password stored in the database, and the two strings tested for equality. This means that a session key is valid for the day of issue, forcing the user to log in again the next day.
The
username is passed to the Java client as a parameter in the
<APPLET> tag so that it can be passed to the ITX gateway
when the Java client requests that a page be added to the favourites.
The user authentication functions reside in the userfuncs.inc
script on the ITX Gateway. Any script that requires user functionality calls
the validUser() function, which has the following return values:
Due to time restrictions on the client-side, it was not possible to fully integrate user authentication. Therefore, only one dummy user was set up in order to demonstrate the concept of users and their preferences. An obvious extension of this would be to extend this to allow multiple users.
From inception, the design of the server-side of the Teletext system was intended to be as modular as possible. Thus the system is scalable to whatever extent required in many different situations and server loads. Modules have been created under the one umbrella of the 'server', although there can be in fact multiple servers running potentially on multiple machines, performing different tasks. The following architecture was decided on for the servers:
This enables multiple servers of the same type to be added to the system:
The Database Server stores Teletext pages that are ready to pass to the client through the ITX Gateway. The purpose of having a cache is to reduce the waiting involved with 'ordinary' Teletext systems (i.e. a television set), when trying to access a page. On a Teletext TV, once the page number has been selected, it is not displayed until the next time that page is transmitted - often a delay of 30 seconds or more. With a cache of pages, the wait can be reduced dramatically.
As the server was to include a cache of pages, some form of storage needed to be arranged to store the pages in. The pages could be stored in either their original format, or could be decoded and stored in our own format and/or as images.
In either case the volume of data stored is fairly large (if we assume that each page is 1 kilobyte in size, there are on average 10 subpages per page number, there are 8 magazines each with pages 00-FF and 5 channels, this gives us a data volume of approximately 1k * 10* 8 * 16 * 16 * 5 = 102400k = 100Mb).
The access times for both writing and reading pages on the server needed to be as short as possible, especially if processing of pages was to be done on the server, in order to shorten the time between a page being requested and being delivered to the remote client. This is particularly important when the number of clients requesting pages (hence the usage of the server) is high. Bearing in mind that the pages are updated almost constantly as well, speed is of the utmost importance in this application and outweighs most other considerations.
These alternative forms of storage for the Teletext pages were considered:
From these alternatives there were three clear reasons for using a third-party database system.
Firstly, the fact that several databases were freely available should not be overlooked. It would have been wasteful to ignore this fact and implement our own system in the limited time available.
Secondly, a good database system's heuristics for caching data in main memory make it much faster than implementing our own system purely on disk.
Finally, the database could have additional features such as usage statistics et cetera, which could be difficult to achieve if we implemented our own system, and could easily be used to our advantage.
MySQL was chosen as the database system we should use, for the following reasons:
MySQL is well integrated into PHP, a server-side, embedded scripting language. The server group considered that PHP was a good choice to form database queries, see the ITX Gateway section for more details on the choice of PHP.
It was originally decided to come up with a heuristic algorithm, which would update pages in the server's 'spare time', according to how often we expected pages to be updated. Pages requested would, if not in the database already, be collected from the receiver at the earliest opportunity, and there would be an option of retrieving a fresh page in case the cached page was out of date.
However, when we found that we could retrieve Teletext pages in real time, as they were received, we decided that it would be better to update the database with the new pages each time the page was received. In this way, the pages in the database will always be up to date, and there is no need to ignore the cached copy of a page. This is assuming that we are only using one channel - if the receiver skips to another channel, there will be a period when pages from the other channels will not be updated. For this reason, it would be better to be able to use more than one receiver to fill the database. The system was designed with this in mind.
When choosing how to update the server with new Teletext pages, our ideas about distributability suggested that we should use a network-based paradigm even if the decoder was in the same physical machine as the database. UDP was selected, as it is widely supported, and is a well known standard on the Internet. It suits the size of a Teletext page (about 1kb), and the low header-size reduces overheads. Originally, a central ITX server was to communicate with the database also using UDP. This was changed since the functionality could be delivered most effectively using a PHP script to access the database directly, from the ITX gateway.
The Database needed to receive new pages from the server, and a protocol was suggested for this. The original protocol was as follows: channel_number, page_number, subpage_number, ft1_page_number, ft1_subpage_number, ft2_page_number, ft2_subpage_number, ft3_page_number, ft3_subpage_number, ft4_page_number, ft4_subpage_number, fti_page_number, fti_subpage_number, timestamp, prev_timestamp.
This was modified due to the fact that the actual Teletext data had been totally ignored! Once this had been added to the protocol, it remained in that form. The protocol was originally to be in an ASCII string form as the data field of a UDP packet, but this was eventually abandoned in favour of sending a 'struct' since the respective parts of the system were both in the C language, and this removed the need to extract the information from the protocol.
The server code put the information into the database using the mySQL C API which is provided as a library with mySQL.
The mySQL server was originally set up with the following tables:
| Table | Column | Comments |
|---|---|---|
| Users | *login | string |
| name | string | |
| password | encrypted string | |
| (Home-page) | hex-int |
This table holds the users' login information.
| Table | Column | Comments |
|---|---|---|
| Userpages | **login* | string |
| *page | hex-int |
This table stores the user's list of bookmarks, or favourites. When a user decides to add a bookmark, a new row is added to the table with the user's login and that page number.
| Table | Column | Comments |
|---|---|---|
| Textdata | *channel | dec-int |
| *pagenumber | hex-int | |
| *subpagenumber | dec-int | |
| FTlink1 | hex-int | |
| FTlink2 | hex-int | |
| FTlink3 | hex-int | |
| FTlink4 | hex-int | |
| FTindexlink | hex-int | |
| data | binary 40 bytes * number of rows | |
| flags?? | binary | |
| updatetime | time :- the time it was last updated | |
| updatedbefore | time :- the time before last |
** = foreign key * = partial key
The Textdata table is the main part of the database. It holds the cache of Teletext pages. The pages are held as individual subpages in each row. The primary key is the combination of channel, page number and subpage number. Fastext links are stored as separate columns. The data is stored in binary format.
The tables had to be changed as the project evolved. First of all, the pagenumbers were stored as strings to avoid confusion between hex and decimal values. A preference - 'Floating Toolbar' was added to the Users table.
| Table | Column | Comments |
|---|---|---|
| Users | *login | varchar(10)binary |
| name | varchar(30)binary | |
| password | varchar(32)binary | |
| homechannel | smallint(6) | |
| homepage | smallint(6) | |
| homesubpage | smallint(6) | |
| floatingtoolbar | tinyint(1) |
A simple description field was added to the bookmarks table.
| Table | Column | Comments |
|---|---|---|
| Userpages | **login* | varchar(10)binary |
| *channel | smallint(6) | |
| *pagenumber | smallint(6) | |
| *subpagenumber | smallint(6) | |
| description | tinyblob |
Fastext link subpage numbers were added to the Textdata table. A timestamp was added, to show when it was added to the database.
| Table | Column | Comments |
|---|---|---|
| Textdata | *channel | int(11) |
| *pagenumber | varchar(4) | |
| *subpagenumber | varchar(4) | |
| FTlink1 | varchar(4) | |
| FTlink1sub | varchar(4) | |
| FTlink2 | varchar(4) | |
| FTlink2sub | varchar(4) | |
| FTlink3 | varchar(4) | |
| FTlink4sub | varchar(4) | |
| FTlink4 | varchar(4) | |
| FTlink4sub | varchar(4) | |
| FTindexlink | varchar(4) | |
| FTindexlinksub | varchar(4) | |
| data | blob | |
| flags | tinyblob | |
| updatetime | int(11) | |
| updatedbefore | int(11) | |
| time | timestamp(14) |
Finally, this table was added to store information about which decoder(s) are working on which channel(s).
| Table | Column | Comments |
|---|---|---|
| chandec | *decoder | int(11) |
| *channel | smallint(6) |
And this one to store frequency information for each channel.
| Table | Column | Comments |
|---|---|---|
| chanfreq | *channel | smallint(6) |
| frequency | float(10,2) |
The database itself is a standard installation of MySQL, which is free software. It comes with an API for the C language, in the form of a library (mysql.h). This was used in a C program which is the heart of the server.
The server program itself is a
fairly simple concept. First of all, it sets up the connection to the MySQL
database. This is done using the mysql_real_connect function in
the API. Once connected, the ITX database is selected. Then a UDP socket is
created and bound to a port number. (This is found by querying
/etc/services using getservbyname()) Then the
program enters a loop. In this loop, a UDP packet is received from the socket,
and it contains a struct itxpacket. This struct contains all of
the data required to fill a row in the textdata table. First, an SQL query is
formed which replaces the 'updatedbefore' column with the 'updatetime' column
for the relevant page:
REPLACE INTO textdata SET
updatedbefore=updatetime WHERE channel = '%i' AND pagenumber = '%s' AND
subpagenumber = '%s'
It does not matter if this row does not already exist in the database. The various elements of the struct are placed into a query as follows:
REPLACE INTO textdata VALUES('%i',
'%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s',
'%s', '%s', NULL, NULL)
The queries are run on the database by
using the mysql_query() function. This puts the page into the
database. The two NULL columns are the 'updatedbefore' and
'timestamp' columns.
The variables are then freed and the loop starts another iteration.
When the server program is invoked, this is not
the only process which starts. Another process is fork()ed off as
follows:
A Reaper which sleeps for three hours, then
runs the SQL query: DELETE LOW_PRIORITY from textdata WHERE time <
(NOW()-30000). This removes all pages which have been unchanged in the
database for more than three hours. This is to stop the pages which fall out
of use from accumulating in the database. It also removes pages which have had
errors in their page number (e.g. p3E8), as these are unlikely to be
retransmitted with the same error. It will not remove pages which are
regularly transmitted as these will have had their timestamp updated when the
most recent one was received. The reaper then loops and sleeps again...
The standard TCP/IP communication systems between various parts of the system means that they can all reside on different machines - perhaps separated by many thousands of miles. Also, the database server can accept input from many decoders at the same time. In this way, more than one channel can be updated at the same time, leaving fewer 'currency gaps' in the database. This requires no change in configuration of the server and extra decoders can be added without a restart of the server. There would eventually be an upper limit on how many decoders could feed to a single server but considering the fact that 5 channels of data can be contained in less than 128 Mb of RAM, and that the server CPU usage is very low, the limit would be fairly high!
It would have been easy to show the distributability of the system by running the decoder on one machine, the database on another, and the ITX server on yet another (and it would have increased the performance of the javaless generation/searching etc). Unfortunately the lab machines were not set up correctly to compile much of our code and so we had to run everything on one machine.
It would be nice to find some way (e.g. a central database of databases) of finding your nearest ITX database server. At the moment the address is hard-coded in, but it could even be passed as a command line argument. The same is true for the decoders/page servers. It would also be nice to find an easy way for these to multicast data to several servers at once.
A channel information
server was partially implemented. This listens on a TCP socket (for which it
gets the port number by querying /etc/services as before) for a
connection from a page server. It then passes the channel frequencies to that
page server, from the chanfreq table in the database. This would have been key
in supporting a more widely distributed setup of the ITX system, accounting
for stations in other countries and regional variations.
The Page Grabber is responsible for retrieving the Teletext data from Teletext-decoding hardware and requesting to the Database Servers that pages it has received be updated in the server-side cache of pages. The Page Grabber communicates with the Database Server by means of UDP packets containing page information.
From the outset there were two hardware devices that could be used for the decoding of the raw Teletext feed - the external Teletext decoder or the internal PCI Hauppauge WinTV card. There were advantages and disadvantages to using each of the cards, but the decision was finally taken to use the WinTV card for the following reasons:
Closely coupled with the choice of decoder card was the choice of Operating System. The two viable options considered were Windows NT and Linux. Upon carrying out extensive research into the utilities and documentation available it was decided to use the Linux platform to run the Page Grabber, largely because of the available Video4Linux API (http://roadrunner.swan sea.uk.linux.org/v4l.shtml). The Video4Linux project provides a common API for many different makes and models of TV tuner card, as long as a driver is available. This means that the Page Grabber can be written using generic Video4Linux calls, and will work on multiple TV tuner cards without modifications to the code.
The Windows NT option did not allow direct access to the Teletext stream of data, but instead used Dynamic Data Exchange (DDE) to interact with reliance on closed third-party software over which the group has no control. DDE does not allow access to the fastext link information. The resulting programs would be WinTV card specific, as Windows currently does not have the concept of a common API for VBI access.
Communication between the Page Grabber and the Database Server could be made either by connection-oriented TCP or datagrams in the form of UDP. TCP has the advantage that it has built-in error handling, and data is guaranteed to arrive at the destination. However, it has the disadvantage of the overhead in setting up a connection. UDP has no such overhead as it is not connection-oriented. Since an update request will only consist of a single page of Teletext plus some header information (approximately 1K in total), this will fit into one UDP packet. In view of these facts, it was decided to use UDP for communication between the Page Grabber and the Database Server for the following specific reasons:
C++ was chosen as the language for the Database Server as it allows a blend of high- and low- level instructions that enable the software to access the VBI data directly.
The Page Grabber communicates with the Database Server to send updates of pages it receives. As mentioned previously, UDP is be used to send these updates. The Page Grabber constructs a struct defined as follows:
typedef struct {
int channel;
char page[5];
char subpage[5];
char f1page[5];
char f1subpage[5];
char f2page[5];
char f2subpage[5];
char f3page[5];
char f3subpage[5];
char f4page[5];
char f4subpage[5];
char indexpage[5];
char indexsubpage[5];
char data[1000];
} itxpacket ;
This is done on an arbitrary port as defined on the Page Grabber in the
/etc/services file.
It must also communicate with the TV
card to tune into particular channels. This is achieved using the
ioctl() system call. For more detailed information, see the
Implementation section below.
To understand how the grabber decodes the data stream it is necessary to describe how the Teletext data is transmitted:
Page data is transmitted in rows, each mapping directly to the 40 character on-screen row. Row 0 is a header row, the format of which is:

To facilitate a degree of error correction in important parts of the row - in the case of the header row (row 0) this is bytes 3 to 10 inclusive - the data is transmitted as a hamming code, each byte containing four message bits interleaved with four protection bits.
Subsequent rows have the first 5 bytes in common with the header row, but are then followed by 40 bytes of page data. Each byte consists of a 7-bit character code with a odd parity bit.
The rows of a page need not be transmitted in order, but must first start with a header row. It is know when the complete row has been transmitted as the header row of the next page is received. Pages are split into magazines - from 1 to 8, which are identified by the first character of the page number. Pages from differing magazine may be interleaved, but only one page per magazine can be transmitted at any one time.
Further data is transmitted on rows 25 to 31, but most of these are not related to Teletext. The only one that is, is Row 27 which provides the page numbers of the fastext links (the text of which are transmitted on Row 24). This is in the following format:
The first byte of the data (3 bytes offset from the start of the row) is ignored. The next 36 bytes are unhammed, giving a resulting 18 bytes. Each link is represented by 3 bytes as follows:
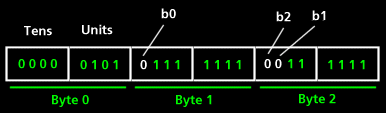
The magazine offset is given using the bits labelled as b0, b1, b2 where b0 is the least significant bit. This value is then XOR'ed with the current magazine number to give the destination magazine. The tens and units columns are contained in byte 0, the first nibble being the page number units, and the second being the page number tens.
The information supplied in the document "Fast-Text mysteries unveiled" on the transmission of the fastext links was found to be misleading as it specified that the magazine offset bits be found in nibbles 3 and 5 of the packet shown above (counting from 0). However, from painful observation it became clear that the diagram above is correct. This is due to differing endian-ness between the document and the Page Grabber. The document also specified that the magazine offset bits give the offset compared to the current magazine. It is not simply that, but as specified above, the XOR of the current magazine and the offset.
After extensive work it was unfortunately
found impossible to retrieve the VBI data and decode it satisfactorily. This
was partially hampered by a poor television signal initially. In the
interests of the best solution possible, it was decided to use Open Source
program, vbidecode, provided as part of the bttv driver bundle to
retrieve the Teletext pages, and modify the program to perform our specific
functions. This decision was made because the use of the raw VBI stream gives
a vastly improved page update time, as opposed to the request-response method
that would be used otherwise. Therefore this implementation guide gives
details of the vbidecode program but concentrates on the
modifications made to it.
The objects used by the program are as follows:
For more detailed
information regarding the vbidecode program, please refer to the
bttv home page (http://www.metzlerbros.de/bttv.html
).
The main program structure is of the following form:
#define SWITCH_TIME 10 // Time between switching channels in minutes...
main() {
while(true) {
tuneControl.flipChannel();
last_chan_switch = time(NULL);
ifstream("/dev/vbi0");
while(fin && (time(NULL) < (last_chan_switch + SWITCH_TIME*60))
{
fin.read(data, VBI_BPF);
(VBIdecoder)vbid.decode(data);
}
fin.close()
}
The program firstly tunes the decoder card in to the correct channel. This is a multi-faceted process: The card must be instructed to do the following:
This is achieved using the
ioctl() system call to issue commands to the WinTV card. The
prototype of this function is int ioctl(int d, int request, ...)
where d is an open file descriptor to /dev/video (the device we
wish to control). The cmd parameter specifies the command to
send. These commands are defined in the file videodev.h for ease
of use. The third parameter is a pointer to the parameters of the command,
which can be a struct or a simple data type depending on the
command.
As described above, we must firstly use the television
channel (note that the terminology of the API is not necessarily intuitive as
a channel refers to the input device - TV or Camera - as opposed to the
conventional use of the word). This uses the VIDIOCGSCHAN
command to firstly get the characteristics of channel 0, then
VIDIOCSCHAN command to set. Both are passed a struct
video_channel as a parameter. If the result of the ioctl
is less than 0, an error has occurred. A discrepency between the Video4Linux
API specification and the bttv driver behaviour was found while using this
command. The Video4Linux API specifies that an integer should be passed as a
parameter for the VIDIOCGSCHAN command. However, when this was
used, an ioctl error was received. Upon investigation of the bttv driver
source code, it was found that the command was expecting a struct
video_channel as a parameter. The group informed both the bttv driver
author and the Video4Linux group as it is unclear which is the correct
behaviour.
vc.channel = 0;
if(ioctl(vdev, VIDIOCGCHAN, &vc) < 0) {
perror("ioctl VIDIOCGCHAN");
}
if(ioctl(vdev,VIDIOCSCHAN,&vc) < 0) {
perror("ioctl VIDIOCSCHAN");
} The
next step is to change to PAL mode. It must be checked that the card supports
PAL first, which is done by using the VIDCGTUNER command, passing
a struct video_tuner as a parameter. This sets various flags,
including VIDEO_TUNER_PAL which then be checked. Assuming the
card supports PAL, this is then selected using the VIDIOCSTUNER
command.
vt.tuner = 0;
if(ioctl(vdev, VIDIOCGTUNER, &vt) < 0) {
perror("ioctl VIDIOCGTUNER");
}
if(!(vt.flags & VIDEO_TUNER_PAL)) {
printf("Error: Tuner doesn't support PAL!\n");
exit(1);
}
vt.mode = VIDEO_MODE_PAL;
if(ioctl(vdev, VIDIOCSTUNER, &vt) < 0) {
perror("ioctl VIDIOCSTUNER");
}
The final stage
is to set the frequency. This achieved using the VIDIOCSFREQ
command. The parameter specifies the frequency as an integer of 1/16th MHz.
if(ioctl(vdev, VIDIOCSFREQ, &newfreq) < 0) {
perror("ioctl VIDIOCSFREQ");
} A utility
get_frequency was written to assist in tuning the device, that
displays the current frequency. It is used in conjunction with a program such
as xawtv, which displays the television signal. Once the desired
frequency is set by manually fine-tuning published frequencies,
get_frequency is run to obtain the current value in 1/16th MHz.
Note that the complete Video4Linux API can be found at http://roadrunner.s wansea.uk.linux.org/v4lapi.shtml.
Once this initialisation of the
card is complete, the server opens the stream device file
/dev/vbi which is provided by the bt848 driver as mentioned
previously, and gives the continuous stream of VBI data. Each frame of data
is passed to an instance of the VBIdecoder object for decoding:
In order to decode the stream of data, the program must first synchronise to the start of a Teletext data packet. This is done by passing the stream into a buffer byte, bit by bit, until the starting sequence of two clock run-in bytes of 0x55 (01010101) followed by the framing code of 0xe4 (11100100) is found. Unfortunately, the WinTV card does not synchronise the bytes received from the television signal to the byte-representation that is passed to the stream input. Thus, the bit-stream must be offset on receiving the clock run-in and the framing code so that the beginning of a byte in the array representation is the same as that as that according to the synchronisation bits.
Once the bit-stream is synchronised, the row number received is examined. The decoding process is different depending on the Row received as some are discarded as they are not related to the Teletext information (such as PDC). Row 0 is unhammed to obtain the current page number and any flags associated with the page. Page information is taken from rows 1-24, and fastext data from row 27.
It is known when an entire page has been
received since a Row 0 not corresponding to the same page as the last Row 0,
is transmitted. At this point, the last page is sent to the database using
the VTpage.write() method. This method constructs a UDP packet
of the form struct itxpacket described in the itx.h
header file - see also Interfaces. This is then transmitted to the Database
Server for addition to the database. The communcation port to use is
ascertained using a system call getservbyname() that looks in the
Page Grabber's /etc/services file for a port number mapped to a
serice, in the ITX server case, the entry is itxserver. This
enables the port to be changed with ease.
vbidecode In the true nature
of GPL programs, generic changes have been fed back to the author for
inclusion in the next release of the software if he deems them to be
necessary. So as to make changes to the code clear, amendments have included
a comment with the word ITX in it, so they can be easily found.
There are many possible extensions to the Page Grabber had more time and resources been available:
vbidecode is a useful
component to use in the project and it makes little sense to reinvent the
wheel, it may have further flaws in it's interpretation of the specification,
and it would be desirable to write the Page Grabber entirely from scratch,
without reliance on a third party program. The code was tested incrementally during production. In addition to this user acceptance testing is required to ensure that the system as a whole is suitable and usable for the intended audience.
There were two potential customers identified for ITX. Firstly large companies or organisations wanting to provide detailed information to ensure they have a well informed workforce, either in addition to, or instead of newspapers. The second method would be to host ITX on a web page with an advertising banner at the top of the page to generate revenue. Market research would be required to establish the size of the potential audience for this service. In both cases copyright issues would need to be resolved because the information content of Teletext is protected.
Considering these markets, the potential users can be identified. A company or organisation can be expected to already have a network of computers, one on most desks. Therefore it can be expected that users will be accustomed to using a computer for tasks such as word processing, as a minimum, and possibly the internet as well. A user visiting the web page with advertising can be expected to be accustomed to the Internet. It must not be discounted that users in this environment may be computer experts. It is very unlikely that users who have never used a computer before will use the system.
Possible Users -
To be effective, sample users from each of these groups would need to evaluate the system.
There are several other factors potentially affecting the response of an individual user depending on the experience of the items listed below.
There are two operational states, firstly when the user knows nothing about the system and uses it cold and secondly when the user has read most of the user guide. Also both the Java and Javaless version require evaluation.
The sample space for potential users is quite large when each of the potential combination of factors, type of user and interface client. Each combination would need to be investigated to ensure as many user requirements as possible are catered for.
One possible method for doing this would be to invite a representative sample of potential users to try out the system. Before looking at the system, a simple questionnaire asking questions about the user's background could be asked. An example is shown (see later). The question regarding age is included to ensure that subconscious assumptions have not been made during development. Then the user would be told about the idea of putting Teletext on the web and would be provided with information about the features provided, such as:
The user would then be invited to try out the both implementations of the client and after a brief familiarisation period, a series of tasks which represent each of the features outlined above. The user's response could then be timed and observed to see which tasks could be instinctively carried out.
A second questionnaire could then be posed to ask specific questions about the UI and a more informal talk about likes and dislikes could be used to establish more "feel" based feed back.
The potential disadvantage with giving two separate questionnaires is that responses to both questionnaires need to be considered together. It might be better to give both questionnaires after the trial. Also users could become accustomed to potentially strange surroundings whilst completing the first questionnaire.
A second group of users could then be asked to read the user manual to provide a more in depth knowledge of the system. This group could either be the same people as before or different ones. The advantage of using the same people is that it directly models the instinctive desire to try a new "toy" and then read the documentation afterwards. Also the sample of people would be the same so there would be no bias introduced between the two sets by random choice. The disadvantage would be that users would have already spent a long while evaluating the system and consequently may lose interest, and thus not communicate their potentially valuable views. There is also a danger that users may be evaluating the user guide at this point, rather than ITX and although this would be valuable information, at this stage in the design process - feedback on the system itself is more valuable.
The delivery for the questions and initial information needs to be as constant as possible to minimise the chance of the tester learning what users find difficult and hence giving extra help. As this is a web based product it seems appropriate that a web based form should be used for the questionnaires and introductory text. A form can be used to collect responses, which can then be automatically stored electronically for further analysis. This also has the advantage that a large number of users from many countries could potentially evaluate the system. A user doing the second phase of investigation could read the online version of the manual. In the case of evaluating office workers who are unlikely to be familiar with the web is would be necessary to provide paper based versions of these documents.
It was not possible to implement the testing strategy outlined above due to time constraints and a lack of suitably enthusiastic volunteers. Throughout the development of the user interfaces much informal feedback was provided by friends. Suggestions such as "Can we change the size of the text page so that it looks better at the resolution on my monitor?", "Why not put the channel logos on the up and down channel buttons", "Can we centre the Teletext page in the window?" were acted upon and made it into the final version.
Thank you for taking the time to answer the following questions. Please select the appropriate most answer from the choices listed, if appropriate, or fill in your answer.
Q1 Age
Q2a Have you used Teletext on a TV?
Q2b Have you used fastext on a TV?
Q2c Have you used Teletext on a computer before?
Q3 How often do you use Teletext?
Q4 Which items types of software are you familiar with? The items in brackets are examples.
Q5 Do you have a computer at home?
Q6 Do you think you would use Teletext if available on your computer?
At home?
Q6b At Work?
ITX provides many of the features provided by a normal television such as hold, reveal and fastext links as well as additional features such as clickable page number links to go to other pages, Clickable mail and URL links to e-mail and open web address, favourites to enable pages to be found again, search for finding information and text only mode.
Please attempt to complete the following list of tasks in order before continuing (you may wish to launch a new window for ITX).
Thank you, please complete these final questions.
Q7 Did you prefer the first or second interface?
Q8 Which was the hardest task and in each version and why?
Q9 What would you change in either interface and why?
Q10a Having seen ITX do you think it could be useful?
At home
Q10b At work
Q11 Would you use it?
Q12 Do you have any further comments?
Thank you once again for your time.
There were many challenges through all areas of the project. One of the largest challenges for the members of the group was documentation. As Teletext was introduced approximately 25 years ago, the original Specification is somewhat dated and parts of it are open to interpretation by broadcasters. Often the only way to render a page correctly was to program the renderer according to an interpretation of the sometimes contradictory specifications and then tweak it according to the output of a television! By far the greatest challenge that posed the group as a whole was understanding fully the Teletext specification.
Another difficult challenge was for the Server group to access the raw data stream from the TV card. It would have been much easier to use the request based decoder, but that could not achieve the functionality and speed we desired. As a result, a very large amount of time was spent trying to find out how to do this, and in the end, some open source code was used.
The client group cited that one of the greatest challenges presented to them was an intelligent decision on the version of Java to use. Version 1.1 has the advantage that it is supported in far more browsers.
However, it does not ship with JFC (Swing) as standard. On the other hand, Java 1.2 does come with Swing as standard but is not supported widely among browsers. Either version can be used, but only by compiling twice, which is not in the spirit of the Java ethos of 'run anywhere'.
Another challenge has been trying to acheive something different with a project which has been run many times before. We have produced a system which incorporates all of the expected functionality of such a system, and also extends this in other directions, such as to thin handheld devices, whose popularity has only just started to explode.
The group has been dynamic and worked well together. We have all learned a great deal about working on a sizeable project as a team. It speaks volumes that the group all knew each other before the project, and we are all still friends at the end!
Our Project Supervisor, Ian Harries, was both supportive and challenging, as was best for the project. We appreciate the motivation and energy he added.
Thanks must go to the following establishments in South Kensington who have kindly agreed to sponsor this project in return for giving them copious sums of money. They have provided project- and life- saving lab breaks over the last few months:
Thanks also go to the patience, food and support, etc. of Pak, Dave, Mary, Sarah (all of them), Nat, Mary (another one), Georgina and Billy, for being the man.